As agents take on increasingly complex long-horizon tasks, evaluation frameworks are scaling up to match. This post covers some recent work in this area, including deepagent(), a new batteries-included agent for long-horizon tasks and Inspect SWE which brings Claude Code, and Codex CLI agents into Inspect. We also cover new infrastructure for multi-agent timelines, context window compaction, and checkpointing for long-running evaluations.
Deep Agents
deepagent() is a batteries-included agent designed for complex, long-horizon tasks. It extends react() with four key capabilities: subagent delegation, persistent memory, structured planning, and an opinionated system prompt tuned for autonomous execution.
from inspect_ai import Task, task
from inspect_ai.agent import deepagent
from inspect_ai.dataset import json_dataset
from inspect_ai.scorer import includes
from inspect_ai.tool import bash, text_editor
@task
def ctf_challenge():
return Task(
dataset=json_dataset("ctf_challenge.json"),
solver=deepagent(
tools=[bash(), text_editor()],
web_search=True
),
scorer=includes(),
sandbox="docker",
)Deep agents can delegate work to specialized subagents with independent context windows — only summaries return to the parent, preventing context degradation over long trajectories:
research()— Read-only information gathering with no side effects.plan()— Structured task decomposition without tool execution.general()— Full autonomous execution with the parent’s tools.
The agent also includes a memory() tool for offloading important context to persistent storage (surviving compaction events), todo_write() for structured planning and progress tracking, and support for skills — packaged capabilities that agents can discover and use.
See the deep agent documentation for the full details. Note that deepagent() is designed for tasks that benefit from planning, decomposition, and persistent memory. For many benchmarks including more difficult ones like Cybench or Terminal Bench 2.0, react() performs equally well, so always measure against a baseline.
Inspect SWE
The inspect_swe package makes software engineering agents like Claude Code, Codex CLI, Gemini CLI, and Mini SWE Agent available as standard Inspect agents. For example, here we use the claude_code() agent as the solver in an Inspect task:
from inspect_ai import Task, task
from inspect_ai.dataset import json_dataset
from inspect_ai.scorer import model_graded_qa
from inspect_swe import claude_code
@task
def system_explorer() -> Task:
return Task(
dataset=json_dataset("dataset.json"),
solver=claude_code(),
scorer=model_graded_qa(),
sandbox="docker",
)Inspect SWE agents are implemented using the Inspect Sandbox Agent Bridge. Agents run inside the sample sandbox and their model API calls are proxied back to Inspect, so you can use any model with any agent, and features like token limits, time limits, and log transcripts work as normal.
Recent additions to Inspect SWE include:
- Centaur mode — Human-in-the-loop mode where a human operator can observe and intervene.
- Skills support — Agents can discover and use packaged skill definitions for structured capabilities.
- Gemini CLI and Mini SWE Agent — New agent bridges alongside the existing Claude Code and Codex CLI.
- Improved Kubernetes reliability — Use
exec_remote()for more robust execution on k8s clusters.
Timelines
Increasingly, agent scaffolds are utilizing multiple agents to parallelize work and keep context windows coherent. The transcripts created by multi-agent architectures are, however, much harder to read as they aren’t just a simple message history. To address this, we introduce timelines, which automatically detect sub-agents in a transcript and provide a clean view of the main agent trajectory and its calls to sub-agents:
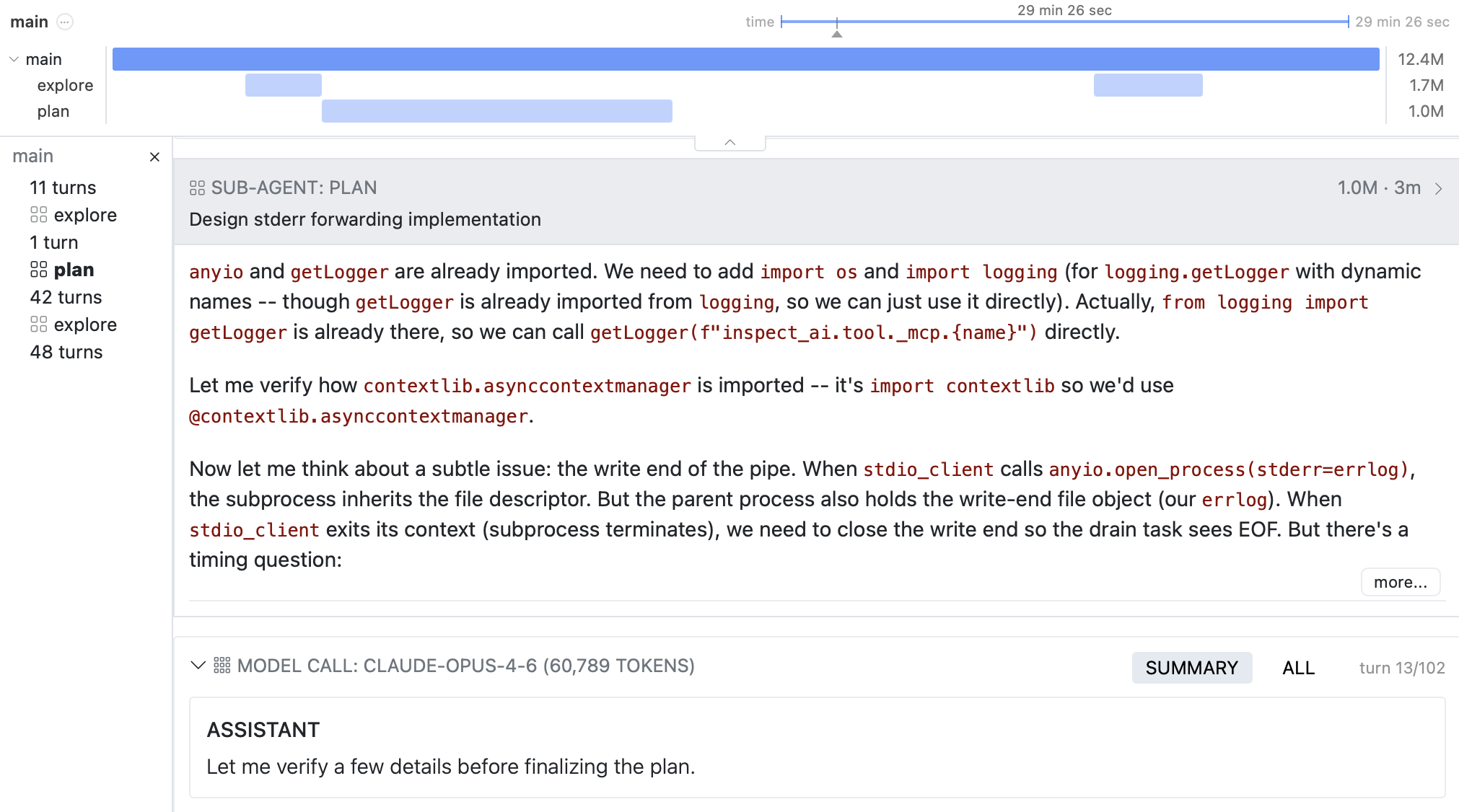
Drill into any sub-agent to view its trajectory:
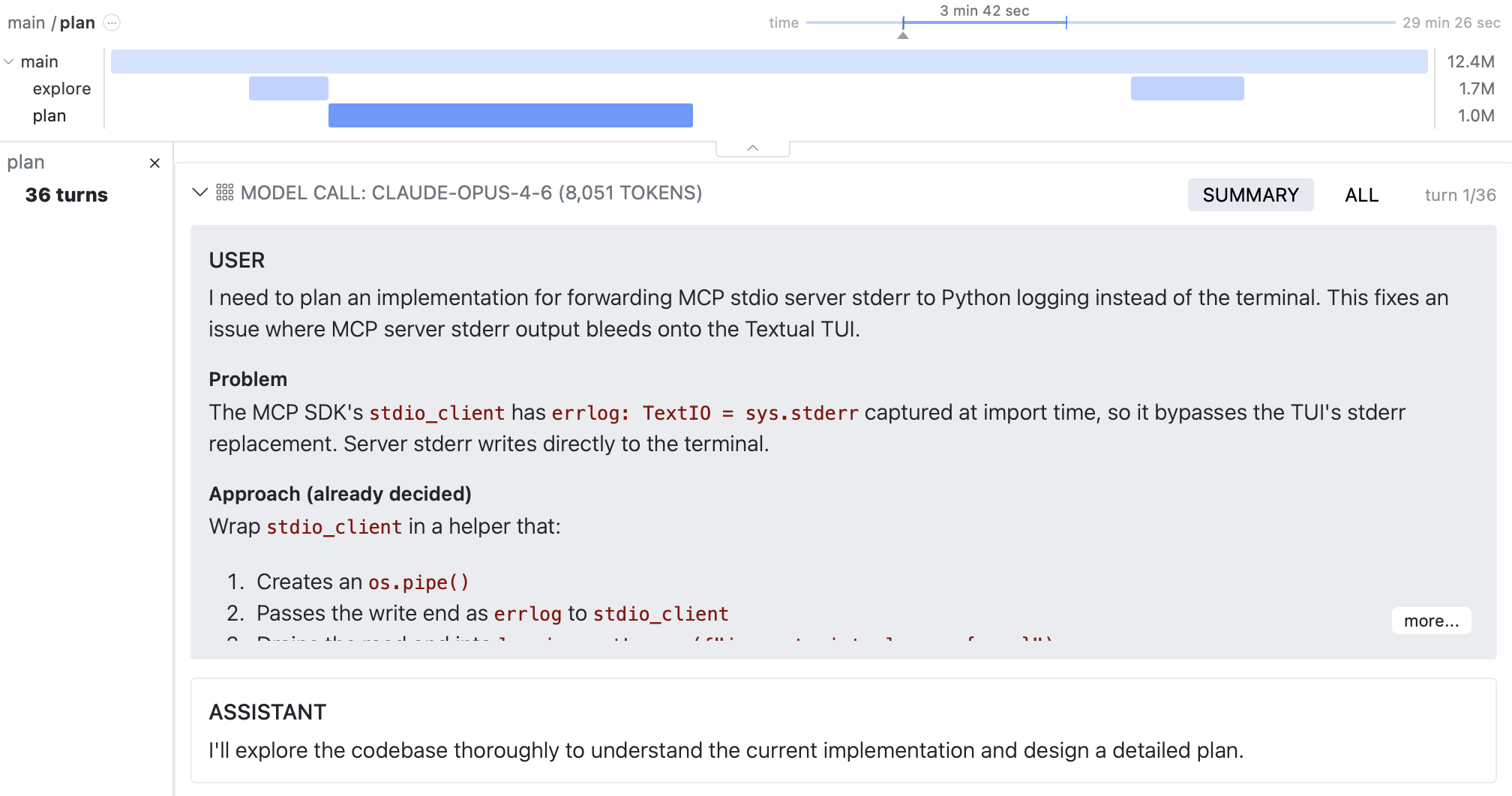
Compaction
Compaction enables you to automatically manage conversation context as it grows, helping you optimize costs and stay within context window limits for long-running agents. Several compaction strategies are available:
| CompactionAuto | Automatic compaction: tries native first, falls back to summary. |
| CompactionNative | Use provider-specific native compaction API (OpenAI and Anthropic only). |
| CompactionSummary | Compact by having a model create a summary of the message history. |
| CompactionEdit | Compact by editing the message history to remove content (e.g. tool call results and reasoning). |
| CompactionTrim | Compact by trimming the message history to preserve a percentage of the input. |
Compaction is built-in to the ReAct Agent, Deep Agent, and the Agent Bridge and can also be added to custom agents. Here are some examples of using compaction with the react() agent:
from inspect_ai.agent import react
from inspect_ai.model import (
CompactionAuto, CompactionEdit, CompactionNative
)
from inspect_ai.tool import bash, text_editor
# automatic compaction (recommended default)
react(
tools=[bash(), text_editor()],
compaction=CompactionAuto()
)
# edit compaction
react(
tools=[bash(), text_editor()],
compaction=CompactionEdit(keep_tool_uses=3)
)Compaction can also make use of the memory() tool to offload important context to files prior to compaction.
Checkpointing
As evaluations grow longer (sometimes running for days or even weeks), a single infrastructure failure can throw away enormous amounts of agent work. We are currently working on a checkpointing feature that will enable agents to save their progress at regular intervals and resume from the last saved point rather than restarting from scratch.
Checkpointing captures the state required for agent resumption, including conversation history, sandbox filesystem state, and the sample’s data store. Resumption will integrate transparently with Inspect’s existing retry machinery. After a crash, inspect eval-set and inspect eval-retry will automatically resume incomplete samples from their latest checkpoint.
We’ve published an RFC for checkpointing. If you’re running long-horizon evaluations we’d love to hear your feedback.